Don’t Overfit! — How to prevent Overfitting in your Deep Learning Models
Base Model
To see how we can prevent overfitting, we first need to create a base model to compare the improved models to. The base model is a simple keras model with two hidden layers with 128 and 64 neurons. You can check it out here:
| model = keras.Sequential() | |
| model.add(keras.layers.Dense(300, activation=tf.nn.relu, input_dim=300)) | |
| model.add(keras.layers.Dense(128, activation=tf.nn.relu)) | |
| model.add(keras.layers.Dense(64, activation=tf.nn.relu)) | |
| model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) | |
| model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) | |
| history = model.fit(df_train, train_labels, batch_size=32, | |
| epochs=100, validation_split=0.2, shuffle=True) |
With this model we can achieve a training accuracy of over 97%, but a validation accuracy of only about 60%. In the graphic below we can see clear signs of overfitting: The Train Loss decreases, but the validation loss increases.
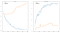
If you see something like this, this is a clear sign that your model is overfitting: It’s learning the training data really well but fails to generalize the knowledge to the test data. With this model, we get a score of about 59% in the Kaggle challenge — not very good.
So, let’s see how we can improve the model
Improving the Score
To improve the score, we can essentially do two things
- Improve our model
- Improve our data
I’ll start by showing you how to change the base model. Then I’ll go into feature selection, which allows you to change the data
Improving our model
I’m going to be talking about three common ways to adapt your model in order to prevent overfitting.
1: Simplifying the model
The first step when dealing with overfitting is to decrease the complexity of the model. In the given base model, there are 2 hidden Layers, one with 128 and one with 64 neurons. Additionally, the input layer has 300 neurons. This is a huge number of neurons. To decrease the complexity, we can simply remove layers or reduce the number of neurons in order to make our network smaller. There is no general rule on how much to remove or how big your network should be. But, if your network is overfitting, try making it smaller.
2: Adding Dropout Layers
Dropout Layers can be an easy and effective way to prevent overfitting in your models. A dropout layer randomly drops some of the connections between layers. This helps to prevent overfitting, because if a connection is dropped, the network is forced to Luckily, with keras it’s really easy to add a dropout layer.
The new, simplified model with dropout layers could look like this:
| model = keras.Sequential() | |
| model.add(keras.layers.Dense(16, activation=tf.nn.relu, input_dim=df_train.shape[1])) | |
| model.add(keras.layers.Dropout(0.4)) | |
| model.add(keras.layers.Dense(8, activation=tf.nn.relu)) | |
| model.add(keras.layers.Dropout(0.4)) | |
| model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) | |
| model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) |
As you can see, the new model only has one hidden layer and fewer neurons. Additionally, I added Dropout layers between the layers with a dropout rate of 0.4.
3: Early Stopping
Another way to prevent overfitting is to stop your training process early: Instead of training for a fixed number of epochs, you stop as soon as the validation loss rises — because, after that, your model will generally only get worse with more training. You can implement early stopping easily with a callback in keras:
| es_callback = keras.callbacks.EarlyStopping(monitor='val_loss', patience=3) | |
| model.fit(df_train, train_labels, callbacks=[es_callback]) |
For this to work, you need to add the validation_split parameter to your fit function. Otherwise, the val_loss is not measured by keras.
Feature Selection
If you take a look at the raw data, you will see that there are 300 columns and only 250 rows.


That is a lot of features for only very few training samples. So, instead of using all features, it’s better to use only the most important ones. This will, on the one hand, make the training process notably faster, on the other hand, it can help to prevent overfitting because the model doesn’t need to learn as many features.
Luckily, scikit-learn provides the great Feature selection Module, which helps you identify the most relevant features of a dataset. So, let’s explore some of those ways!
F-Score Selection
One of the simplest ways to select relevant features is to calculate the F-Score for each feature. The F-Score is calculated using the variance between the features and the variance within each feature. A high F-score usually means that the feature is more important than a feature with a low F-score. You can calculate the F-Scores for the Features like this:
| from sklearn.feature_selection import SelectKBest | |
| from sklearn.feature_selection import f_classif | |
| selector = SelectKBest(f_classif, k=10) | |
| selected_features = selector.fit_transform(train_features, train_labels) |
If you plot the data, you will see something like this:

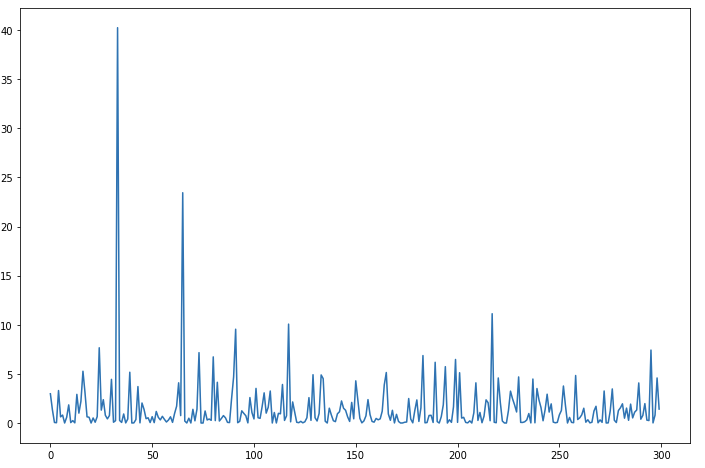
As you can see, the F-score between the features varies greatly. You can get the score for each column with selector.scores_ or you can get the index of the top 10 features like this:
f_score_indexes = (-selector.scores_).argsort()[:10]Recursive Feature Elimination
Another way is the recursive feature selection. Unlike the other method, with RFE you don’t calculate a score for each feature, but you train a classifier multiple times on smaller and smaller feature set. After each training, the importance of the features is calculated and the least important feature is eliminated from the feature set.
| from sklearn.feature_selection import RFE | |
| from sklearn.ensemble import RandomForestClassifier | |
| clf = LinearSVC(C=0.01, penalty="l1", dual=False) | |
| clf.fit(train_features, train_labels) | |
| rfe_selector = RFE(clf, 10) | |
| rfe_selector = rfe_selector.fit(train_features, train_labels) | |
| rfe_values = rfe_selector.get_support() |
You can get the index of these features like this:
rfe_indexes = np.where(rfe_values)[0]Results
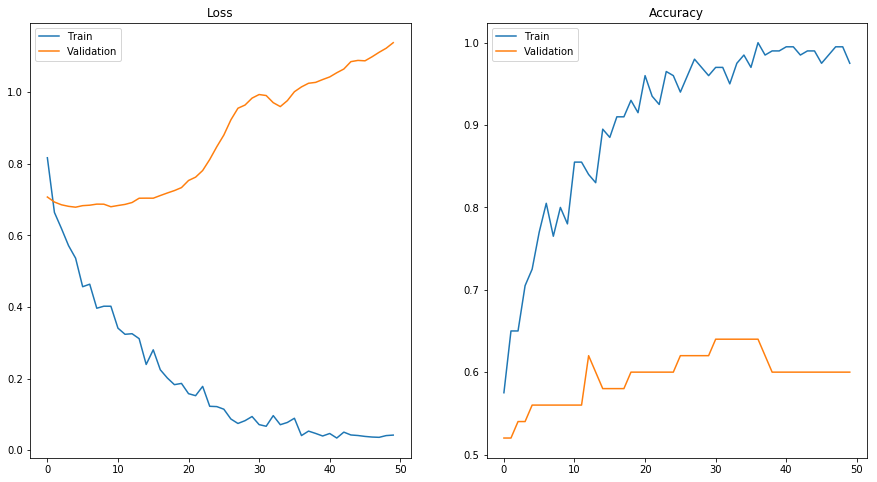
At the beginning of this article, we started with a model which was overfitting and could barely get more than 50% accuracy. Below, you can see the results of the new model, trained on the data after the feature selection:


It’s still not perfect, but as you can see, the model is overfitting way less. In the Kaggle challenge, the new model scores at about 80% — which is 20% better than the base model.



Comments
Post a Comment